递归调用同一个函数,在异步代码里也可以执行
(来自fake-webpack对loader的处理)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47function execLoaders(request, loaders, content, options) {
return new Promise((resolve, reject) => {
if (!loaders.length) {
resolve(content);
return;
}
let loaderFunctions = [];
loaders.forEach(loaderName => {
let loader = require(loaderName);
loaderFunctions.push(loader);
});
nextLoader(content);
/***
* 调用下一个 loader
* @param {string} content 上一个loader的输出字符串
*/
function nextLoader(content) {
if (!loaderFunctions.length) {
resolve(content);
return;
}
// 请注意: loader有同步和异步两种类型。对于异步loader,如 less-loader,
// 需要执行 async() 和 callback(),以修改标志位和回传字符串
let async = false;
let context = {
request,
async: () => {
async = true;
},
callback: (content) => {
nextLoader(content);
}
};
let ret = loaderFunctions.pop().call(context, content);
if(!async) {
// 递归调用下一个 loader
nextLoader(ret);
}
}
});
}用一个数组存放所有要执行的函数,在nextLoader函数里调用每一个数组里的函数。
递归调用nextLoader 函数时,每次将数组pop出来一个区执行。
当数组里某一个函数是异步函数时,设置一个标志位async,这样在nextLoader函数里面就知道里面的函数(也就是数组的某一个元素,假如是a)是异步的,这时暂停递归。当a异步结果回来的之后,再调用callback,调用callback也就是调用nextLoader,此时之前暂时停掉的递归链子又串起来了。
shell编程语法学习
具体内容查看菜鸟教程
一.记录之前的练习文件
1 | #!/bin/bash |
二. 查看和切换shell类型
chsh -s /bin/bash 或者chsh -s /bin/bash 来切换shell类型(-s 代表shell的意思)
echo $SHELL 来查看shell类型
或者使用$0来查看shell类型
vuex源码学习
一. 前言
使用vue的小伙伴们对于vuex应该是非常熟悉的,其作用是使用一个store对象来存储应用层级状态和数据。
放上一张store的图片

store就是这样一个对象。可以看到里面有我们熟悉的commit,dispatch函数,state属性;也有和模块相关的_modules,_modulesNamespaceMap内部属性等等。
使用起来非常简单:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23import Vue from 'vue';
import Vuex from 'vuex';
Vue.use(Vuex);
const store = new Vuex.Store({
state: {
a: 0
},
action: {
action1: ({commit}) => {
// 省略其他步骤,这里一般是一些异步操作
commit('changeA', 10);
}
},
mutations: {
changeA: (state, data) => {
state.a = data;
}
}
}
new Vue({
store,
el: '#app',
});
在组件里1
this.$store.commit('changeA', 2);
就能达到修改state里面的数据a的效果。
这只是最简单的情况,里面还可以有模块划分,getter,插件机制,工具函数等等具体使用可以点击链接。今天我们就可以大概探索一下其中的奥秘,看看它的源码实现。
二. 整体流程分析
根据上面使用案例的代码,发现代码其实也就是做了两个事情:首先执行的是Vue.use(Vuex); 之后将实例化的一个Vuex.Stored的实例当做参数传进Vue里。
对于第一个事情,vue的插件都是通过在使用Vue.use()时自动调用了插件的install方法进行初始化。所以vuex只需要定义好install函数,然后业务方调用一下vue的use函数,就可以了。
对于第二个事情,就得看看Vuex导出的Store构造函数干了什么。
综上所述我们要看两个东西:一个是install函数,另一个是Store构造函数。
1. install函数
1 | export function install (_Vue) { |
applyMixin里面主要代码:1
2
3
4
5
6
7
8
9
10
11
12Vue.mixin({ beforeCreate: vuexInit })
function vuexInit () {
const options = this.$options
// store injection
if (options.store) {
this.$store = typeof options.store === 'function'
? options.store()
: options.store
} else if (options.parent && options.parent.$store) {
this.$store = options.parent.$store
}
}
由此可以看出:
vuex的install函数里面做了两件事:
(1) 限定vuex只可以被安装一次
(2) 给vue的每个实例注入store
其中比较重要的是第二件事:在beforeCreate生命周期函数里自动执行注入$store属性。这样所有的组件只要是有options.parent属性,就能在beforeCreate的时候传入store。
但是注意一点:自己new出来的组件是需要手动传入store的。
2. Store构造函数
在具体学习之前,先看看执行Store构造函数生成实例的一些重要过程,留个印象:
- 生成一个ModuleCollection实例this._modules,得到根模块。
- 递归生成每个模块,并记录模块之间的层级关系(注意模块之间的层级结构是通过数组path来体现的)
- 将dispatch和commit函数绑定this为当前store实例
- 递归安装this._modules里的每一个模块
- 将子模块的state放进根级state属性里
- 将模块内的mutaions actions getters 与命名空间进行绑定
- 执行resetStoreVM,让store.getters具有响应式
(1)首先可以看下Store的constructor函数(只列出重要代码)
1 | constructor (options = {}) { |
首先定义了一些实例属性,包括_committing , _actions, _actionSubscribers, _mutations等等。这里可以看一下this._modules = new ModuleCollection(options) 这句代码,它生成了一个ModuleCollection实例,一个模块集合。我们看看ModuleCollection构造函数
(2)ModuleCollection类
ModuleCollection构造函数里只执行了一个register函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16register (path, rawModule, runtime = true) {
const newModule = new Module(rawModule, runtime)
if (path.length === 0) {
this.root = newModule
} else {
const parent = this.get(path.slice(0, -1))
parent.addChild(path[path.length - 1], newModule)
}
// register nested modules
if (rawModule.modules) {
forEachValue(rawModule.modules, (rawChildModule, key) => {
this.register(path.concat(key), rawChildModule, runtime)
})
}
}
register函数里得到了一个Module实例newModule。
如果是根模块的话,就将newModule赋值给root属性;否则将当前模块和父模块使用addChild方法建立关联(在module实例的_children数组上添加一个元素)。
接着处理子模块:根据我们之前调用Store构造函数时传的对象(rawModule)里的modules字段, 生成了子模块。
注意在生成子模块的时候传入的path变成了path.concat(key),path数组里元素的顺序代表着模块之间的关系。 例如1
2path = ['m1', 'm2'];
// 意思是根模块下有一个m1模块,m1模块下有一个m2模块。
下面我们看看前面提到的Module类。
(3) Module类
constructor (rawModule, runtime) {
this.runtime = runtime
// Store some children item
this._children = Object.create(null)
// Store the origin module object which passed by programmer
this._rawModule = rawModule
const rawState = rawModule.state
// Store the origin module's state
this.state = (typeof rawState === 'function' ? rawState() : rawState) || {}
}
这个对象有3个重要属性:
a. 一个模块的子模块(_children属性,一个数组)
b. 传入的用于生成module的config对象(_rawModule)
c.模块内的state对象
其中state对象是公有属性,其他两个是内部的私有属性
每个实例有几个重要方法:用于操作child子模块的方法
addChild (key, module) {
this._children[key] = module
}
removeChild (key) {
delete this._children[key]
}
getChild (key) {
return this._children[key]
}
这几个方法在实例化ModuleCollection调用register时会被使用,用来记录模块之间的层级关系,上面的代码已经列出。
(4)回到Store的构造函数
所以当代码执行到Store构造函数的this._modules = new ModuleCollection(options) 时,已经生成了一个ModuleCollection实例(this._modules),this._modules的root属性指向了根模块。同时递归生成了各个子模块。
与此同时,其他属性也通过Object.create(null)得到了一个初始值null
(5)绑定dispatch和commit函数的作用域
1 | // Store构造函数里的代码 |
commit和dispatch是类似的,这里以commit为例:
这段代码缓存了Store类原型上的commit的方法,将在commit方法绑定this为根级store对象。这段代码的作用就是绑定commit方法的this对象。
接下来执行的是installModule方法
(6)installModule方法
1 | function installModule (store, rootState, path, module, hot) { |
获取所安装模块的命名空间,如果命名空间存在,就在_modulesNamespaceMap对象上存起来。
const local = module.context = makeLocalContext(store, namespace, path)
这句是生成一个与store类似的context对象,里面的commit和dispatch方法都是与当前模块的命名空间进行了关联,可以在模块内不需要关注当前命名空间是什么,state拿到的也是当前模块的state,当然如果你想拿到根级别state或者store也是可以拿到的。总之makeLocalContext的作用是让命名空间使用起来更方便,让内部代码不用关注当前命名空间。
(7)在installModule里面注册mutation,action和getter
三个类似,这里拿mutaion举出例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15forEachMutation (fn) {
if (this._rawModule.mutations) {
forEachValue(this._rawModule.mutations, fn)
}
}
function forEachValue (obj, fn) {
Object.keys(obj).forEach(key => fn(obj[key], key))
}
function registerMutation (store, type, handler, local) {
const entry = store._mutations[type] || (store._mutations[type] = [])
entry.push(function wrappedMutationHandler (payload) {
handler.call(store, local.state, payload)
})
}
上面代码其实就是对每一个mutation先处理他的namespace,把自身type和namespace拼接得到最终名字,
然后执行registerMutation,registerMutation就是在store._mutations[type]里面添加一个handle,这个handler是这个mutation被commit的时候会被调用的。
同时将这个handler的this绑定为store实例对象,并传入模块内部state,所以模块内部的mutation直接能拿到模块内部的state来使用。
所以这一部分作用就是绑定命名空间和this对象,并将模块内state传入mutation。
(8)递归调用installModule方法。
module.forEachChild((child, key) => {
installModule(store, rootState, path.concat(key), child, hot)
})
对每一个modules对象调用installModule方法。
注意在子模块执行installModule的时候下面代码会被执行
if (!isRoot && !hot) {
const parentState = getNestedState(rootState, path.slice(0, -1))
const moduleName = path[path.length - 1]
store._withCommit(() => {
Vue.set(parentState, moduleName, module.state)
})
}
这段代码的作用是将子模块的state添加到根级state上。我们传入的state是按照模块区分的,而这部分代码将所有的state合成了一个大的state对象。并且利用Vue.set实现数据响应式,让state改变触发视图的改变。
(9)resetStoreVM函数
installModulec彻底执行完之后,开始执行resetStoreVM,resetStoreVM作用是让store.getters具有响应式。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45function resetStoreVM (store, state, hot) {
const oldVm = store._vm
// bind store public getters
store.getters = {}
const wrappedGetters = store._wrappedGetters
const computed = {}
forEachValue(wrappedGetters, (fn, key) => {
// use computed to leverage its lazy-caching mechanism
computed[key] = () => fn(store)
Object.defineProperty(store.getters, key, {
get: () => store._vm[key],
enumerable: true // for local getters
})
})
// use a Vue instance to store the state tree
// suppress warnings just in case the user has added
// some funky global mixins
const silent = Vue.config.silent
Vue.config.silent = true
store._vm = new Vue({
data: {
$$state: state
},
computed
})
Vue.config.silent = silent
// enable strict mode for new vm
if (store.strict) {
enableStrictMode(store)
}
if (oldVm) {
if (hot) {
// dispatch changes in all subscribed watchers
// to force getter re-evaluation for hot reloading.
store._withCommit(() => {
oldVm._data.$$state = null
})
}
Vue.nextTick(() => oldVm.$destroy())
}
}
这段代码是生成了一个名叫_vm的vue实例,利用vue实例的computed属性可以让每一个getter都能实现数据响应。1
2
3
4
5
6
7
8forEachValue(wrappedGetters, (fn, key) => {
// use computed to leverage its lazy-caching mechanism
computed[key] = () => fn(store)
Object.defineProperty(store.getters, key, {
get: () => store._vm[key],
enumerable: true // for local getters
})
})
从这段代码可以看出,store.getters对象里的每一个属性对应值其实就是store._vm[key]的值。
三. 帮助函数解析
vuex的帮助函数有5个: mapState, mapMutations, mapGetters, mapActions, createNamespacedHelpers.
具体功能就不细说了,大家可以查看官网。这里主要讲一下他们的实现。
以mapState为例:
先说如何使用masState1
2
3
4
5
6
7
8
9
10
11
12
13
14 // 或者
computed: {
...mapState({
'a',
'bb': 'b'
}
}
// 或者
computed: {
...mapState({
a: state => state.some.nested.module.a
b: state => state.some.nested.module.b
})
}
再看代码实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// 代码一
export const mapState = normalizeNamespace((namespace, states) => {
const res = {}
normalizeMap(states).forEach(({ key, val }) => {
// computedFn函数:
res[key] = function mappedState () {
let state = this.$store.state
let getters = this.$store.getters
if (namespace) {
const module = getModuleByNamespace(this.$store, 'mapState', namespace)
if (!module) {
return
}
state = module.context.state
getters = module.context.getters
}
return typeof val === 'function'
? val.call(this, state, getters)
: state[val]
}
// mark vuex getter for devtools
res[key].vuex = true
})
return res
})
其中normalizeNamespace方法传入一个函数(这里暂时叫fn)
并返回一个函数(这里暂时叫fn2)。normalizeNamespace作用就是将fn函数的第一个参数作为命名空间,并将命名空间做了绑定,如没有传入命名空间,则认为是根模块。
具体实现可以看下面代码:1
2
3
4
5
6
7
8
9
10
11
12// 代码二
function normalizeNamespace (fn) {
return (namespace, map) => {
if (typeof namespace !== 'string') {
map = namespace
namespace = ''
} else if (namespace.charAt(namespace.length - 1) !== '/') {
namespace += '/'
}
return fn(namespace, map)
}
}
所以mapState函数就可以理解为绑定了作用域的fn函数。当我们执行mapState时,就可以理解为执行了fn。所以我们继续看代码一里面传入normalizeNamespace里面的函数(也就是我们说的fn函数)。
这个fn函数返回的是一个对象,并且对象每个属性名是传入参数对象的属性名,属性值是一个函数(我们暂时称为computedFn)。而我们使用的时候是在vue的computed里面使用的,使用代码上面也列出了,读者可以返回去看看。
所以我们就知道了为什么平时要用1
...mapState({})
的形式来使用。
computedFn函数里获取到了指定命名空间的context对象里的的state和getter(所以我们在mapState的时候可以获取到模块内部的state和getter)。
computedFn返回的值是根据调用mapState时候传进来的第二个参数确定的(如不传命名空间,则这根据第一个参数确定)。1
2
3
4
5
6
7
8
9
10
11
12
13
14 // 或者
computed: {
...mapState({
'a',
'bb': 'b'
}
}
// 或者
computed: {
...mapState({
a: state => state.some.nested.module.a
b: state => state.some.nested.module.b
})
}
上面列出的两种情况,结合代码理解:
- 如果val是一个函数,那就执行这个函数并将命名空间内的state和getters传进去执行;
- 如果是val不是函数,就认为是一个字符串,则将这个字符串作为state的属性来获取state值返回。
2. createNamespacedHelper函数
有了上面的基础,那么createNamespacedHelper函数简单了。
首先看createNamespacedHelper的使用1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import { createNamespacedHelpers } from 'vuex'
const { mapState, mapActions } = createNamespacedHelpers('some/nested/module')
export default {
computed: {
// 在 `some/nested/module` 中查找
...mapState({
a: state => state.a,
b: state => state.b
})
},
methods: {
// 在 `some/nested/module` 中查找
...mapActions([
'foo',
'bar'
])
}
}
再看实现:1
2
3
4
5
6export const createNamespacedHelpers = (namespace) => ({
mapState: mapState.bind(null, namespace),
mapGetters: mapGetters.bind(null, namespace),
mapMutations: mapMutations.bind(null, namespace),
mapActions: mapActions.bind(null, namespace)
})
就是返回了mapState, mapGetters,mapMutations, mapActions四个函数并绑定了一下命名空间而已。
四. 插件机制
vuex插件实质是一个函数,vuex会将store传入插件函数。在插件函数内部,可以利用store.subscribe和store.subscribeAction两个函数来达到监听commit mutaion和dispatch action的目的。
store.subscribe和store.subscribeAction是类似的,我们以subscrib为例看看源码实现:
store维护了一个数组_subscribers,执行subscrib函数时,将传入的参数fn放入_subscribers,当commit了一个mutation的时候,就会调用_subscribers数组里的每一个元素,也就是之前传入的每一个fn。使用这种方式可以达到监听commit mutation的作用。
1 | commit (_type, _payload, _options) { |
1 | subscribe (fn) { |
如果大家有兴趣可以去看看vuex自带的logger插件的代码,会发现这个插件做的事情很简单:就是之后对比一下commit mutaion之前的state和之后的state,并将新旧两个state和触发state改变的mutation打印出来,仅仅做了这些操作。
vuex自带的logger插件的代码在这里就不展示了,大家可以自行去guthub上看。
五. 严格模式
开启严格模式,仅需在创建 store 的时候传入 strict: true1
2
3
4const store = new Vuex.Store({
// ...
strict: true
})
在严格模式下,无论何时发生了状态变更且不是由 mutation 函数引起的,将会抛出错误。这能保证所有的状态变更都能被调试工具跟踪到。
我们看看源码实现:1
2
3
4
5
6
7function enableStrictMode (store) {
store._vm.$watch(function () { return this._data.$$state }, () => {
if (process.env.NODE_ENV !== 'production') {
assert(store._committing, `do not mutate vuex store state outside mutation handlers.`)
}
}, { deep: true, sync: true })
}
代码利用vue的监听函数对this._data.$$state做了监听。这里注意store._vm是一个vue实例,是在resetStoreVM方法对getter实现响应式的时候创建的(上面有提到)。而$$state就是我们vuex的state。这里对整个state做监听,当state发生变化时,去判断如果store._committing为false,那么说明不是有commit触发的对state的改变,而是用户自己手动修改的state的值,这时候就会报错。
五. 结语
了解了store的真面目之后是不是感觉非常简单呢,相信大家使用起来也会更加顺手啦。与此同时,我们也可以在此基础上学习vuex源码中对于子module的管理方式,以一种树的结构来管理模块,相信这种思想在在其他地方也可以使用到呢。
总之,看源码不仅仅是可以了解它的原理,方便自己更好地使用,也可以学习其代码风格和思路,举一反三,融会贯通,逐渐形成自己的思想和风格哦~
关于正则表达式
本文内容是参照菜鸟教程写的
一. 对元字符分类
正则表达式里面可以分为普通字符和元字符。
普通字符没有特殊含义,比如’a’ 就是代表 ‘a’ 字符;而元字符具有特殊含义,下面我们将元字符进行简单归类,便于记忆。(只列出平时使用较多的一些字符,不常使用的没有列出)
1 非打印字符
| 元字符 | 含义 |
|---|---|
| \s | 匹配任何空白字符,包括空格,制表符,换页符等等。(space) |
| \S | 匹配任何非空白字符 |
| \n | 匹配一个换行符 (line) |
| \r | 匹配一个回车符(return) |
2 特殊含义元字符
| 元字符 | 含义 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 \n 或 \r。要匹配 $ 字符本身,请使用\$。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,此时它表示不接受该字符集合。要匹配 ^ 字符本身,请使用 \^。 |
| * | 匹配前面的子表达式0次或多次。要匹配 * 字符,请使用 \*。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用\{。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用\[。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。’\n’ 匹配换行符。序列 ‘\\’ 匹配 “\”,而 ‘\(‘ 则匹配 “(“。 |
| | | 指明两项之间的一个选择。要匹配 | 请使用 \ | |
3 和转义相关的元字符
| 字符 | 描述 |
|---|---|
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \w | 匹配字母、数字、下划线。等价于[A-Za-z0-9_]。 |
| \W | 匹配非字母、数字、下划线。等价于[^A-Za-z0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配”never” 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。(boundary) |
| \B | 匹配非单词边界。’er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,’(.)\1’ 匹配两个连续的相同字符。 |
4 限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。比如 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m}。
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo 能匹配 “z” 以及 “zoo”。 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,’zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,”do(es)?” 可以匹配 “do” 、 “does” 中的 “does” 、 “doxy” 中的 “do” 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,’o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,’o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。’o{1,}’ 等价于 ‘o+’。’o{0,}’ 则等价于 ‘o*’。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,”o{1,3}” 将匹配 “fooooood” 中的前三个 o。’o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
*、+限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
eg:
1 | var str = '<H1>Chapter 1 - 介绍正则表达式</H1> |
贪婪:下面的表达式匹配从开始小于符号 (<) 到关闭 H1 标记的大于符号 (>) 之间的所有内容。
1 | /<.*>/ |
非贪婪: 下面的表达式只匹配开始的 H1 标签
1 | /<.*?>/ |
通过在 *、+ 或 ? 限定符之后放置 ?,该表达式从”贪心”表达式转换为”非贪心”表达式或者最小匹配。
5 定位符
定位符使您能够将正则表达式固定到行首或行尾。它们还使您能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
定位符用来描述字符串或单词的边界,^ 和 $ 分别指字符串的开始与结束,\b 描述单词的前或后边界,\B 表示非单词边界。
正则表达式的定位符有:
| 字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
6 选择
用圆括号将所有选择项括起来,相邻的选择项之间用|分隔。但用圆括号会有一个副作用,使相关的匹配会被缓存,此时可用?:放在第一个选项前来消除这种副作用。
1 | var reg = /a(\w)+(f|g)/ |
1 | var reg = /a(?:\w)+(f|g)/ |
第一个例子和第二个例子相比,str.match(reg)返回的结果不包括”e”
7 反向引用
对一个正则表达式模式或部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。缓冲区编号从 1 开始,最多可存储 99 个捕获的子表达式。每个缓冲区都可以使用 \n 访问,其中 n 为一个标识特定缓冲区的一位或两位十进制数。
1 | var str = "Is is the cost of of gasoline going up up"; |
8 非捕获元字符
| 字符 | 描述 |
|---|---|
| (?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 “或” 字符 (\ | ) 来组合一个模式的各个部分是很有用。例如, ‘industr(?:y | ies) 就是一个比 ‘industry | industries’ 更简略的表达式。 |
| (?=patt) | 正向肯定预测(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,”Windows(?=95 | NT | 2000)”能匹配”Windows2000”中的”Windows”,但不能匹配”Windows3.1”中的”Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!patt) | 正向否定预测(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如”Windows(?!95 | 98 | NT | 2000)”能匹配”Windows3.1”中的”Windows”,但不能匹配”Windows2000”中的”Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?<=patt) | 反向(look behind)肯定预测,与正向肯定预查类似,只是方向相反。例如,”(?<=95 | 98 | NT | 2000)Windows”能匹配 “2000Windows” 中的 “Windows” ,但不能匹配 “3.1Windows” 中的 “Windows” 。 |
| (?<!patt) | 反向否定预测,与正向否定预查类似,只是方向相反。例如”(?<!95 | 98 | NT | 2000)Windows”能匹配”3.1Windows”中的”Windows”,但不能匹配”2000Windows”中的”Windows”。 |
二. 对元字符进行归总
| 字符 | 描述 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,’n’ 匹配字符 “n”。’\n’ 匹配一个换行符。序列 ‘\‘ 匹配 “\” 而 “(“ 则匹配 “(“。 |
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo 能匹配 “z” 以及 “zoo”。 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,’zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,”do(es)?” 可以匹配 “do” 或 “does” 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,’o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,’o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。’o{1,}’ 等价于 ‘o+’。’o{0,}’ 则等价于 ‘o*’。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,”o{1,3}” 将匹配 “fooooood” 中的前三个 o。’o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 “oooo”,’o+?’ 将匹配单个 “o”,而 ‘o+’ 将匹配所有 ‘o’。 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用像”(.\ | \n)“的模式。 |
| (pattern) | 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 ‘(‘ 或 ‘)‘。 |
| (?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 “或” 字符 (|) 来组合一个模式的各个部分是很有用。例如, ‘industr(?:y\|ies) 就是一个比 ‘industry\|industries’ 更简略的表达式。 |
| (?=pattern) | 正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,”Windows(?=95\|98\|NT\|2000)”能匹配”Windows2000”中的”Windows”,但不能匹配”Windows3.1”中的”Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如”Windows(?!95\|98\|NT\|2000)”能匹配”Windows3.1”中的”Windows”,但不能匹配”Windows2000”中的”Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?<=pattern) | 反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,”(?<=95 | 98 | NT | 2000)Windows”能匹配”2000Windows”中的”Windows“,但不能匹配”3.1Windows“中的”Windows“。 |
| (?<!pattern) | 反向否定预查,与正向否定预查类似,只是方向相反。例如”(?<!95 | 98 | NT | 2000)Windows“能匹配”3.1Windows“中的”Windows“,但不能匹配”2000Windows“中的”Windows“。 |
| x|y | 匹配 x 或 y。例如,’z|food’ 能匹配 “z” 或 “food”。’(z|f)ood’ 则匹配 “zood” 或 “food”。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’、’l’、’i’、’n’。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,’[a-z]’ 可以匹配 ‘a’ 到 ‘z’ 范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,’[^a-z]’ 可以匹配任何不在 ‘a’ 到 ‘z’ 范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配”never” 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
| \B | 匹配非单词边界。’er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
| \cx | 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配字母、数字、下划线。等价于’[A-Za-z0-9_]’。 |
| \W | 匹配非字母、数字、下划线。等价于 ‘[^A-Za-z0-9_]‘。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,’\x41’ 匹配 “A”。’\x041’ 则等价于 ‘\x04’ & “1”。正则表达式中可以使用 ASCII 编码。 |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,’(.)\1’ 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |
三. 获取字符串中匹配正则的部分
可以使用正则的方法,或者字符串的方法
1 正则实例的方法:
(1) exec方法(获取匹配正则部分)
1 | var reg = /\d+/; |
(2)test方法(测试是否匹配正则)
1 | reg.exec(str); // true |
2 字符串的方法
(1)match方法
1 | var reg = /(\d+)(f|g)/; |
1 | var reg = /\d+/g; |
注意:正则的exec方法和字符串的match方法功能一样,但是正则的exec永远只返回第一个匹配字符串及其子模式。而字符串的match方法在正则不设置g时和exec一致,如果设置了g,那么返回的是所有匹配的字符串,并且不包括子模式。
四. 返回结果中正则子模式的顺序
1 | reg = /a((\w)+)(f|g)/ |
result[0] 是整个匹配到的模式
result[1]是第一个匹配到的子模式
result[2]是第一个子模式里面的匹配到的子模式
result[3]是第二个匹配到的子模式
所以这个返回数组排列是按照类似深度遍历的模式来排列匹配数组的
关于babel的一些理解
一. 为什么要使用babel
由于有些浏览器不支持es6+ 语法,而我们在写代码的时候又希望能使用es6语法,享受其带来的简单方便。这时候我们需要babel来对我们的代码进行转换,将es6+ 语法转换成es5语法,让浏览器能识别。
二. 什么是babel
babel是一个转译器,感觉相对于编译器compiler,叫转译器transpiler更准确,因为它只是把同种语言的高版本规则翻译成低版本规则,而不像编译器那样,输出的是另一种更低级的语言代码。
(1) babel的编译过程可以分成三个步骤:
- The parser:
@babel/parser(解析:将代码转换成AST) - The transformer[s]: All the plugins/presets (转换:访问AST几点进行转换生成新的AST)
- These all use
@babel/traverseto traverse through the AST
- These all use
- The generator:
@babel/generator(生成:以新的AST为基础生成代码)
(2) babel工作流:input string -> @babel/parser parser -> AST -> transformer[s] -> AST -> @babel/generator -> output string
(3) babel包的构成:
核心包
- babel-core: babel转译器本身,提供了babel的转译API,如babel.transform等,用于对代码进行转译。像webpack的babel-loader就是调用这些API来完成转译过程的。
- babel-parser:babel的词法解析器
- babel-traverse:用于对AST抽象语法树的遍历,主要给plugin用
- babel-generator:根据AST生成代码
工具包
- babel-cli:babel的命令工具,通过命令对js代码进行转译
- babel-register:通过修改nodejs的require来自动转译require引用的js代码文件
功能包
- babel-type: 用于检验,构建和改变AST树的节点
- babel-template:辅助函数,用于从字符串形式的代码来构建AST树的节点
- babel-helpers: 一系列预制的babel-template函数,英语提供给一些plugins用
- babel-code-frames:用于生成错误信息,指出错误位置
- babel-plugin-xxx:bable转译过程中用到的插件。其中babel-plugin-transform-xxx是transform步骤中使用到的
- babel-preset-xxx:transform阶段使用到的一系列plugin
- babel-polyfill:js标准新增的原生对象和API的shim,实现上仅仅是对core-js和gennerator-runtime两个包的封装
- babel-runtime:功能类似于babel-polyfill,一般用于library或plugin中,因为他不会污染全局作用域
preset其实就是一些plugin的集合
三. polyfill和runtime
由于babel默认只是转译新标准引入的语法,比如ES6的箭头函数转译成ES5的函数;而新标准引入的新的原生对象,部分原生对象新增的原型方法,新增的API(如Iterator、Generator、Set、Maps、Proxy、Reflect、Symbol、Promise等全局对象等)以及一些定义在全局对象上的方法(比如Object.assign),这些babel是不会转译的。需要用户自行引入polyfill来解决
引入垫片(polyfill)有几种方式,其中他们各有优缺点:
方法一:使用babel-polyfill
1. 先安装包: npm install –save babel-polyfill
2. 要确保在入口处导入polyfill,因为polyfill代码需要在所有其他代码前先被调用
代码方式: import "babel-polyfill"
或者webpack配置: module.exports = { entry: ["babel-polyfill", "./app/js"] };
优点:引入之后可以放心使用es6语法,他对所有的方法都进行了polyfill
缺点:这种方式是改变的全局作用域,也就是说污染了全局(比如在Array的prototype上添加includes方法等)
打出来的包也会比较大。
方法二:使用transform-runtime
让重复定义变成重复引用,解决babel代码重复问题
babel-plugin-transform-runtime插件依赖babel-runtime,babel-runtime是真正提供runtime环境的包;也就是说transform-runtime插件是把js代码中使用到的新原生对象和静态方法转换成对runtime实现包的引用,举个例子如下:
1 | // 输入的ES6代码 |
优点:从上面这个例子可见,原本代码中使用的ES6新原生对象Symbol被transform-runtime插件转换成了babel-runtime的实现,既保持了Symbol的功能,同时又没有像polyfill那样污染全局环境(因为最终生成的代码中,并没有对Symbol的引用)
缺点:但是由于他不能污染全局环境,所以对于实例上的方法则无法使用,比如[].includes()
不过对于有些类上的静态方法可以使用,比如Array.from方法
方法三:使用babel-preset-env插件
这款preset能灵活决定加载哪些插件和polyfill,不过还是得开发者手动进行一些配置。
1 | // cnpm install -D babel-preset -env |
关于最后一个参数useBuiltIns,有两点必须要注意:
- 如果useBuiltIns为true,项目中必须引入babel-polyfill。
- babel-polyfill只能被引入一次,如果多次引入会造成全局作用域的冲突。
四. core-js介绍
core-js包才上述的babel-polyfill、babel-plugin-transform-runtime、bable-runtime的核心,因为polyfill和runtime其实都只是对core-js和regenerator的再封装,方便使用而已。
但是polyfill和runtime都是整体引入的,不能做细粒度的调整,如果我们的代码只是用到了小部分ES6而导致需要使用polyfill和runtime的话,会造成代码体积不必要的增大(runtime的影响较小)。所以,按需引入的需求就自然而然产生了,这个时候就得依靠core-js来实现了。
core-js的组织结构
首先,core-js有三种使用方式:
默认方式:require(‘core-js’)
这种方式包括全部特性,标准的和非标准的库的形式: var core = require(‘core-js/library’)
这种方式也包括全部特性,只是它不会污染全局名字空间注意文件路径里面有library的就代表是用于类库,不会污染全局作用域的
默认方式和库的形式一个是直接require让其执行而对全局产生影响,另一个是对执行结果赋值(里面的代码不对全局产生影响,只导出一个结果让外部使用)
只是shim: require(‘core-js/shim’)或var shim = require(‘core-js/library/shim’)
这种方式只包括标准特性(就是只有polyfill功能,没有扩展的特性)
core-js的按需使用
1、类似polyfill,直接把特性添加到全局环境,这种方式体验最完整
1 | require('core-js/fn/set'); |
2、类似runtime一样,以库的形式来使用特性,这种方式不会污染全局名字空间,但是不能使用实例方法
1 | var Set = require('core-js/library/fn/set'); |
所以,我理解的babel-polyfill这个包对core-js的引用方式应该是第一种,而babel-runtime对core-js的引用方式是第二种
###总结:babel的难点在于理解polyfill,runtime和core-js,通过本文理解清楚三者之间的关系和区别
babel-polyfill 与 babel-runtime 的一大区别: 前者改造目标浏览器,让你的浏览器拥有本来不支持的特性;后者改造你的代码,让你的代码能在所有目标浏览器上运行,但不改造浏览器。
关于javascript宽高的记录
| client类 | offset类 | scroll类 |
|---|---|---|
| clientWidth: 元素尺寸 (注意不是内容尺寸)+内边距 | offsetWidth: 元素尺寸+内边距+边框 | scrollWidth: 元素尺寸 + 内边距 + 内容超出元素尺寸和内边距的部分 |
| clientHeight:元素尺寸 (注意不是内容尺寸)+内边距 | offsetHeight: 元素尺寸+内边距+边框 | scrollHeight: 元素尺寸 + 内边距 + 内容超出元素尺寸和内边距的部分 |
| clientLeft: border-left的宽度,也就是 border-left厚度 | offsetLeft: 定位祖先元素的外padding到当前元素的外border之间的距离 | scrollLeft: 当元素内容超过元素尺寸的时候,内容被卷起来的宽度,可以理解为滚动条的宽度 可读可写 |
| clientTop: border-top的宽度,也就是border-top厚度 | offsetTop:定位祖先元素的外padding到当前元素的外border之间的距离 | scrollTop: 当元素内容超过元素尺寸的时候, 内容被卷起来的高度,可以理解为滚动条的高度 可读可写 |
获取元素距离视口的坐标:getBoundingClientRect方法,返回的坐标包括元素的边框和内边距,不包括外边距。
获取元素距离文档的坐标:
1
2
3
4
5
6
7
8
9
10function getElePos(ele){
var x = 0,y = 0 ;
while(ele != null ){
x += ele.offsetLeft;
y += ele.offsetTop;
ele = ele.offsetParent;
console.log(ele);
}
return {x : x ,y: y }
}获取视口的大小,也就是窗口的大小:
1 | function getClient(){ |
- 获取文档滚动高度,也就是窗口滚动条高度
1 | function getSCroll(){ |
js判断数据类型
Js判断数据类型一般用的方法有:typeof Object.prototype.toString instance
typeof 用来判断基本数据类型.
返回值包括: boolean, number, string , function , undefined, object, symbol
1
2
3
4
5
6
7typeof true ; typeof Boolean(true) // "boolean"
typeof 4 ; typeof Number (4) // "number"
typeof 'abc' typeof String('abc') // "string"
typeof (function a(){}) // "function"
typeof undefined // "undefined"
typeof null ; typeof {} ; typeof {a: 1} //"object"
typeof Symbol(1) //"symbol"可以使用如下函数判断是否是基本类型:
1
2
3
4
5
6
7
8export function isPrimitive {
return (
typeof value === 'string' ||
typeof value === 'number' ||
typeof value === 'symbol' ||
typeof value === 'boolean'
)
}注意,所有new出来的对象返回都是’object’。
1
typeof(new Number(1)) // "object"
当用typeof 判断出类型不是基本类型(即返回object时),用Object.prototype.toString判断对象构造函数。
可以使用如下函数:
(返回function 和 undefined也可以判断出值得类型了)
1
2
3
4// 判断是否是一个对象(包括用其他构造函数生成的对象)
export function isObject(obj) {
return obj !== null && typeof obj === 'object'
}1
2
3
4// 判断对象是否是纯对象(也就是构造函数是Object)
export function isPlainObject(obj) {
return Object.prototype.toString.call(obj) === '[object Object]'
}使用:
1
2
3
4
5
6const test = {a: 1};
const date = new Date();
isObject(test) // true
isObject(date) // true
isPlainObject(test) // true
isPlainObject(date) // false如上面的date对象,得到isPlainObject(date)为false ,可以用instanceof 判断date是否是某个构造函数的实例
1
date instance Date // true
或者使用下面代码来获取某个实例的构造函数是什么
1
date.constructor.name // "Date"
关于视频的一些总结
一. 视频事件
| 事件名 | 描述 |
|---|---|
| abort | 播放终止时触发。 如视频正在播放,这时拖到开始位置重新播放,就会触发 abort 事件 |
| canplay | 当 ready state 变为 HAVE_ENOUGH_DATA 时触发, 这表示有足够的数据可播放 |
| canplaythrough | 当 ready state 变为 CAN_PLAY_THROUGH 时触发,这表示下载速度在保持当前状态不变的情况下,整个媒体文件可以没有中断的进行播放。注意:在 Firefox 中,手动设置 currentTime 还会触发 canplaythrough 事件 |
| durationchange | 当 metadata 加载结束或修改结束时触发,这表示媒体文件的 duration 发生了变化 |
| emptied | 媒体文件变成空时触发。如媒体文件已经全部或部分加载完,这时调用 load() 去重新加载会触发 emptied 事件 |
| ended | 播放结束时触发 |
| error | 发生错误时触发。元素的 error 属性包含了详细信息。 |
| interruptbegin | 在 Firefox OS 设备,播放的 audio 被中断,或者在 app 中,正在播放 audio 的 app 转为后台运行,或是有更高优先级的 audio 开始播放,都会触发 interruptbegin 事件 |
| interruptend | 在 Firefox OS 设备中,之前中断的 audio 又开始重新播放,或者在 app 中,后台运行的 app 转为前台运行,或当更高优先级的 audio 播放结束,都会触发 interruptend 事件 |
| loadeddata | 媒体文件的第一帧加载完成时触发 |
| loadedmetadata | 媒体文件的 metadata 加载完成时触发 |
| loadstart | 媒体文件开始加载时触发 |
| pause | 播放暂停时触发 |
| play | 暂停之后重新播放时触发。也就是说,先得触发一个 pause 事件,然后重新播放才会触发 play 事件,需要注意的是,这只是一个动作,并不表示立即就会开始播放 |
| playing | 当媒体文件暂停或停止缓冲后,开始播放时触发 |
| progress | 媒体文件正在下载时触发。通过元素的 buffered 属性可以获取已下载的可用的数据 |
| ratechange | 播放速度改变时触发, 即playbackRate属性改变时触发 |
| seeked | seek 操作完成时触发 |
| seeking | seek 操作开始时触发, 拖动进度条的时候会触发seeking事件 |
| stalled | 当 user agent 尝试去拉取数据,但是数据没有传过来时触发 |
| suspend | 媒体文件加载暂停时触发。可能的原因是下载已完成,或是其他原因导致的暂停 |
| timeupdate | 元素的 currentTime 属性发生改变时触发 |
| volumechange | 音量发生改变时触发,可能是设置音量,也可能是修改了 muted 属性 |
| waiting | 当请求的操作(比如播放)因为另一个操作而阻塞时触发(比如 seek) |
loadeddata VS canplay VS canplaythrough
- loadeddata:加载了一些数据
- canplay:加载了足够的数据,这些数据足够开始播放
- canplaythrough:加载了足够的数据,这些数据不仅足够开始播放,也足够结束播放
play VS playing progress
假设我们要播放一个视频,当点击 play 按钮(或调用 play 方法),video.paused 会置为 false,并触发 play 事件,但这并不保证 video 会立即开始播放,它只是尝试去播放。
如果在任意时间点,video 没有足够的数据可用了,它就会暂停(同样的,video.paused 置为 false),并触发 waiting 事件。一旦有了足够的数据(readyState >= HAVE_FUTURE_DATA),就会触发 playing 事件,这时视频会重新开始播放。
因此,play 适合获取动作状态,playing 适合获取播放状态。比如,当触发 waiting 事件时,显示 loading,当触发 playing 事件时,移除 loading。
当用户拖拉进度条的时候,会触发事件 seeking——— play——— wating——— seeked——— playing
所以play事件触发时候可能视频还不能播放,只代表用户的操作;但是playing事件触发的时候,代表视频处于可播放状态
progress
通过元素的 buffered 属性可以获取缓冲数据。
1 | progressEvent ($event) { |
二. 视频属性
可以查看MDN上的HTMLMediaElement元素的属性
error, currentSrc, preload, seeking, paused, played, autoplay, volume, audioTracks, width,height, videoHeight(视频原本的高度),videoWidth(视频原本的高宽度), buffered, currentTime, loop, muted, poster, srcObject(这是一个mediaStream对象), readyState, networkState, duration, playbackRate, ended,controls 等等
三. 视频全屏
视频全屏
判断是否是在全屏状态:
1
2
3isInFullscreen () {
return (document.fullscreenElement || document.mozFullScreenElement || document.webkitFullscreenElement || document.msFullscreenElement)
}进入全屏:
1
2
3
4
5
6
7
8
9
10
11
12requestFullScreen (element) {
if (element.requestFullscreen) {
element.requestFullscreen();
} else if (element.mozRequestFullScreen) {
element.mozRequestFullScreen();
} else if (element.msRequestFullscreen) {
element.msRequestFullscreen();
} else if (element.webkitRequestFullscreen) {
element.webkitRequestFullScreen();
}
this.fullScreen = 1;
}退出全屏:
1
2
3
4
5
6
7
8
9
10
11
12
13exitFullscreen (element) {
// 普通div 需要使用document才能exitFullscreen
// video 可以使用元素本身的exitFullscreen
if (element.exitFullscreen) {
element.exitFullscreen();
} else if (element.msExitFullscreen) {
element.msExitFullscreen();
} else if (element.mozCancelFullScreen) {
element.mozCancelFullScreen();
} else if (element.webkitCancelFullScreen) {
element.webkitCancelFullScreen();
}
}普通div全屏
普通div(假设为container)全屏时注意两个点:
(1)如果container包含video标签和其他div标签,那么在全屏之后video的z-index会特别高,以至于全屏之后只会显示video,其他元素会被隐藏。
解决方法,将需要与video一同全屏显示的标签加上z-indx:2147483647
(2)在调用上面requestFullScreen的时候传入需要全屏的div,但是调用exitFullscreen的时候需要传入document对象才可以退出全屏
我理解的base64编码
一. 为什么需要base64编码
ASCII表里面0到32是控制字符,33开始的才是可见字符。一些只支持纯文本的协议(比如smtp协议)在传输不可见字符的过程中会出现问题,所以为了保险起见,将所有的字符转化成可见字符,这样就不会出错了。
注意:使用命令 man ascii 可以在终端查看ascii码表
二. base64编码的过程
举一个具体的实例,演示英语单词Man如何转成Base64编码。
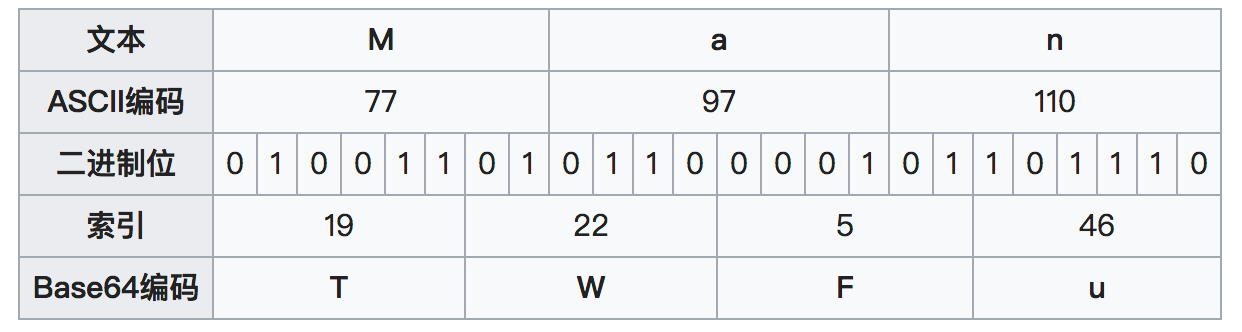
A. 步骤:
第一步,”M”、”a”、”n”的ASCII值分别是77、97、110,对应的二进制值是01001101、01100001、01101110,将它们连成一个24位的二进制字符串010011010110000101101110。
第二步,将这个24位的二进制字符串分成4组,每组6个二进制位:010011、010110、000101、101110。
第三步,在每组前面加两个00,扩展成32个二进制位,即四个字节:00010011、00010110、00000101、00101110。它们的十进制值分别是19、22、5、46。
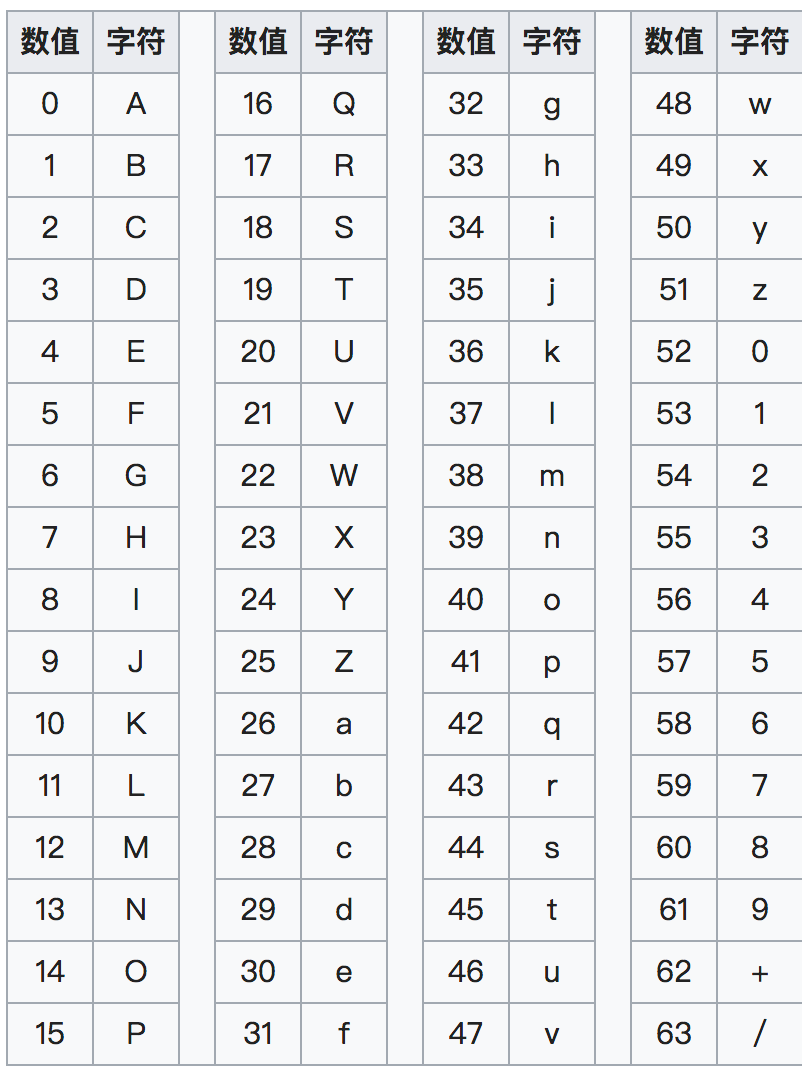
第四步,根据下表,得到每个值对应Base64编码,即T、W、F、u。
在传输的时候,传输的是T、W、F、u所对应的ascii码,而不是man所对应的ascii码。
B. 字节不能整除3的时候:
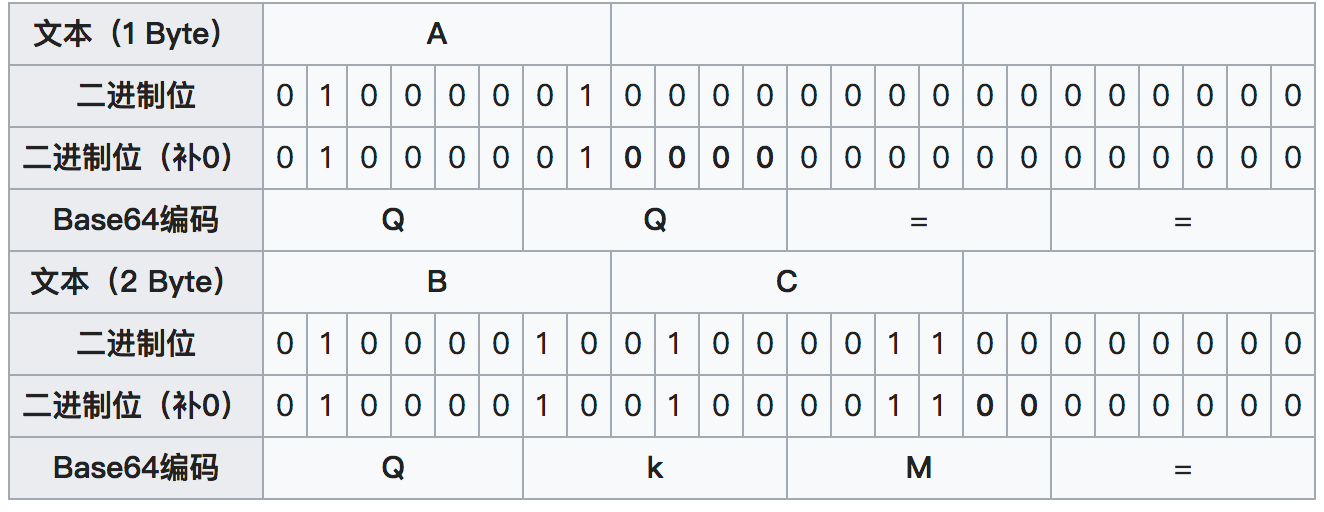
如果要编码的字节数不能被3整除,最后会多出1个或2个字节,那么可以使用下面的方法进行处理:先使用0字节值在末尾补足,使其能够被3整除,然后再进行Base64的编码。在编码后的Base64文本后加上一个或两个=号,代表补足的字节数。也就是说,当最后剩余两个八位字节(2个byte)时,最后一个6位的Base64字节块有四位是0值,最后附加上两个等号;如果最后剩余一个八位字节(1个byte)时,最后一个6位的base字节块有两位是0值,最后附加一个等号。 参考下表
综上所述:
缺点:base64编码会让原本3个字节的字符变成4个字节来存储,加大了33%的存储空间。
优点:让原本不能传输二进制,只能传输文本字符的协议能够传输二进制数据(比如文件,图片等)。
三. 和base64编码相关的使用场景
场景1:给后端上传一个文件
第一种方法: 给后端发送base64编码的字符串。
将文件利用fileRader的readAsDataUrl函数来将文件内容进行base64编码,然后将这个base64字符串发送给后端。
第二种方法:给后端传送一个File文件。
其实这种方法就是将选中的文件里面的内容每8位(1个字节)读取为一个ascii字符(因为一个ascii字符占一个字节),最后得到一个字符串(比如文件内容的二进制总共有24位,3个字节,那么读取得到的就是3个ascii字符组成的字符串),然后将这个字符串就可以代表文件内容(将这三个字符所对应的二进制还原一下,就可以得到真正的原始二进制数据)。前面所说的这个过程可以通过formData自动实现。
1 | // const file = event.target.files[0]; |
场景2: 读取本地图片并且显示
利用fileReader将图片读成base64编码,然后将这个base64编码直接赋值给img的src,就可以显示这张图片了
场景3:
window.atob 把base64字符串进行解码
window.btoa 对字符串进行base64编码
上面两个函数的结果都是字符串。
我理解的这两个过程就是利用base64的编码表(也就是本文第二张图)来进行字符间的映射。
上面的文章中说到了将dataurl变成blob的函数,需要用到window.atob函数
1 | function dataURItoBlob(dataURI) { |
如果原始文本只是英文的话,那么上面得的byteString就是原始字符串。
如果原始文本包含中文的话,那么我们需要将byteString所对应的二进制数据还原,然后再通过二进制数据得到原始文本。因为中文在utf8里面是3个字节表示,不是像英文字符那样一个字节表示。
关于js宽高的记录
| client类 | offset类 | scroll类 |
|---|---|---|
| clientWidth: 元素尺寸 (注意不是内容尺寸)+内边距 | offsetWidth: 元素尺寸+内边距+边框 | scrollWidth: 元素尺寸 + 内边距 + 内容超出元素尺寸和内边距的部分 |
| clientHeight:元素尺寸 (注意不是内容尺寸)+内边距 | offsetHeight: 元素尺寸+内边距+边框 | scrollHeight: 元素尺寸 + 内边距 + 内容超出元素尺寸和内边距的部分 |
| clientLeft: border-left的宽度,也就是 border-left厚度 | offsetLeft: 定位祖先元素的外padding到当前元素的外border之间的距离 | scrollLeft: 当元素内容超过元素尺寸的时候,内容被卷起来的宽度,可以理解为滚动条的宽度 可读可写 |
| clientTop: border-top的宽度,也就是border-top厚度 | offsetTop:定位祖先元素的外padding到当前元素的外border之间的距离 | scrollTop: 当元素内容超过元素尺寸的时候, 内容被卷起来的高度,可以理解为滚动条的高度 可读可写 |
- 获取元素距离视口的坐标:getBoundingClientRect方法,返回的坐标包括元素的边框和内边距,不包括外边距。
- 获取元素距离文档的坐标:
- 获取视口的大小,也就是窗口的大小:
1 | function getViewPortSize(w) { |