一. 为什么需要base64编码
ASCII表里面0到32是控制字符,33开始的才是可见字符。一些只支持纯文本的协议(比如smtp协议)在传输不可见字符的过程中会出现问题,所以为了保险起见,将所有的字符转化成可见字符,这样就不会出错了。
注意:使用命令 man ascii 可以在终端查看ascii码表
二. base64编码的过程
举一个具体的实例,演示英语单词Man如何转成Base64编码。
A. 步骤:
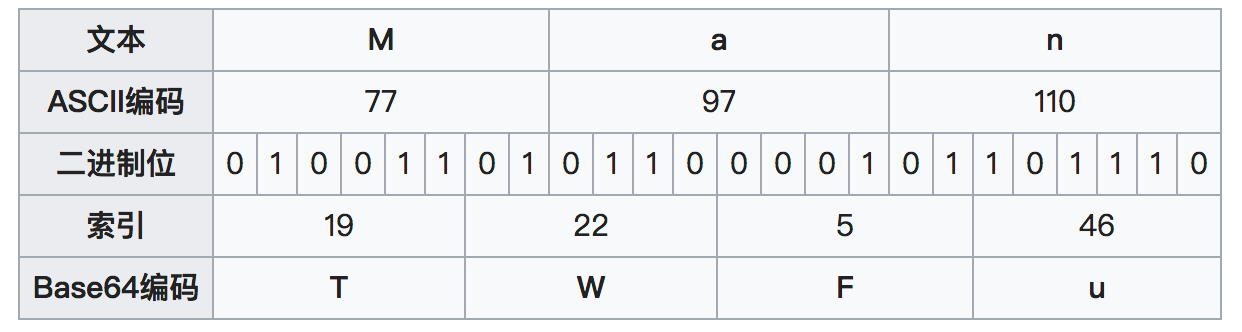
第一步,”M”、”a”、”n”的ASCII值分别是77、97、110,对应的二进制值是01001101、01100001、01101110,将它们连成一个24位的二进制字符串010011010110000101101110。
第二步,将这个24位的二进制字符串分成4组,每组6个二进制位:010011、010110、000101、101110。
第三步,在每组前面加两个00,扩展成32个二进制位,即四个字节:00010011、00010110、00000101、00101110。它们的十进制值分别是19、22、5、46。
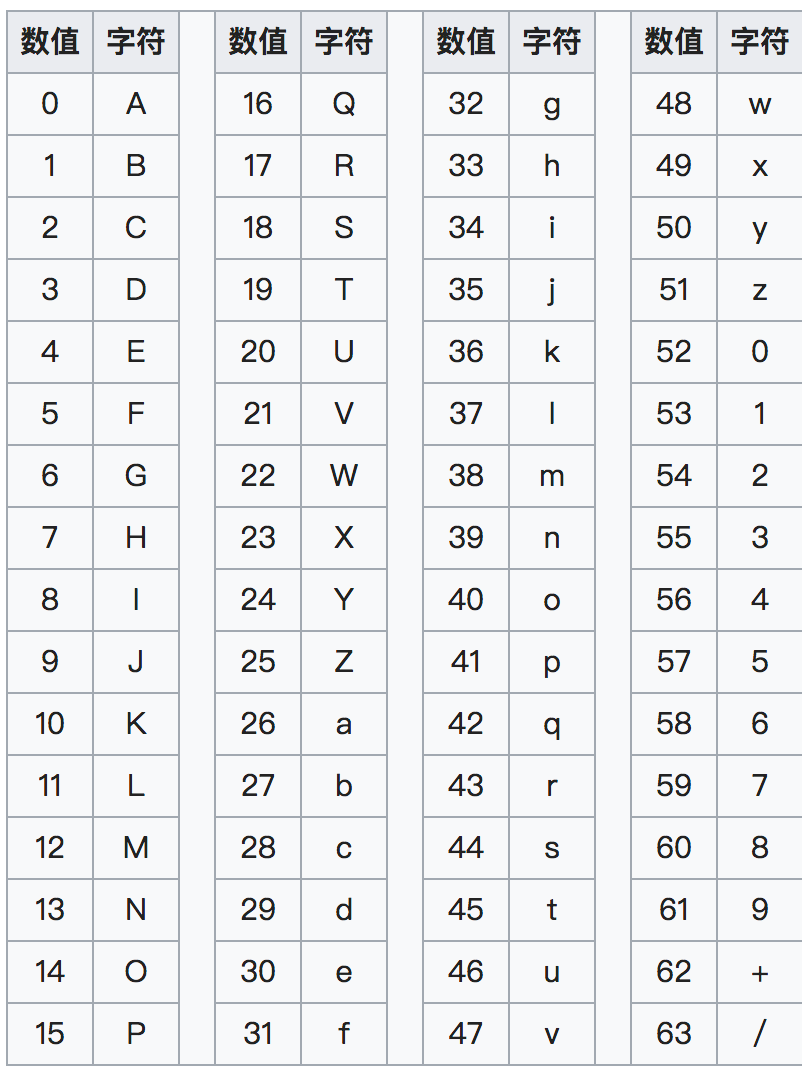
第四步,根据下表,得到每个值对应Base64编码,即T、W、F、u。
在传输的时候,传输的是T、W、F、u所对应的ascii码,而不是man所对应的ascii码。
B. 字节不能整除3的时候:
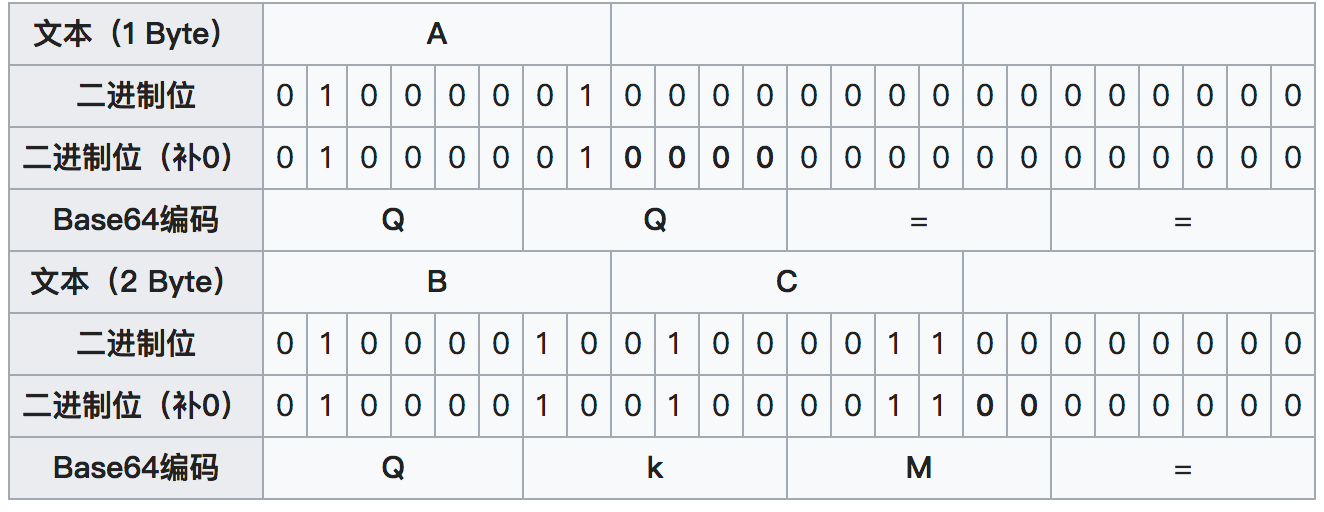
如果要编码的字节数不能被3整除,最后会多出1个或2个字节,那么可以使用下面的方法进行处理:先使用0字节值在末尾补足,使其能够被3整除,然后再进行Base64的编码。在编码后的Base64文本后加上一个或两个=号,代表补足的字节数。也就是说,当最后剩余两个八位字节(2个byte)时,最后一个6位的Base64字节块有四位是0值,最后附加上两个等号;如果最后剩余一个八位字节(1个byte)时,最后一个6位的base字节块有两位是0值,最后附加一个等号。 参考下表
综上所述:
缺点:base64编码会让原本3个字节的字符变成4个字节来存储,加大了33%的存储空间。
优点:让原本不能传输二进制,只能传输文本字符的协议能够传输二进制数据(比如文件,图片等)。
三. 和base64编码相关的使用场景
场景1:给后端上传一个文件
第一种方法: 给后端发送base64编码的字符串。
将文件利用fileRader的readAsDataUrl函数来将文件内容进行base64编码,然后将这个base64字符串发送给后端。
第二种方法:给后端传送一个File文件。
其实这种方法就是将选中的文件里面的内容每8位(1个字节)读取为一个ascii字符(因为一个ascii字符占一个字节),最后得到一个字符串(比如文件内容的二进制总共有24位,3个字节,那么读取得到的就是3个ascii字符组成的字符串),然后将这个字符串就可以代表文件内容(将这三个字符所对应的二进制还原一下,就可以得到真正的原始二进制数据)。前面所说的这个过程可以通过formData自动实现。
1 | // const file = event.target.files[0]; |
场景2: 读取本地图片并且显示
利用fileReader将图片读成base64编码,然后将这个base64编码直接赋值给img的src,就可以显示这张图片了
场景3:
window.atob 把base64字符串进行解码
window.btoa 对字符串进行base64编码
上面两个函数的结果都是字符串。
我理解的这两个过程就是利用base64的编码表(也就是本文第二张图)来进行字符间的映射。
上面的文章中说到了将dataurl变成blob的函数,需要用到window.atob函数
1 | function dataURItoBlob(dataURI) { |
如果原始文本只是英文的话,那么上面得的byteString就是原始字符串。
如果原始文本包含中文的话,那么我们需要将byteString所对应的二进制数据还原,然后再通过二进制数据得到原始文本。因为中文在utf8里面是3个字节表示,不是像英文字符那样一个字节表示。